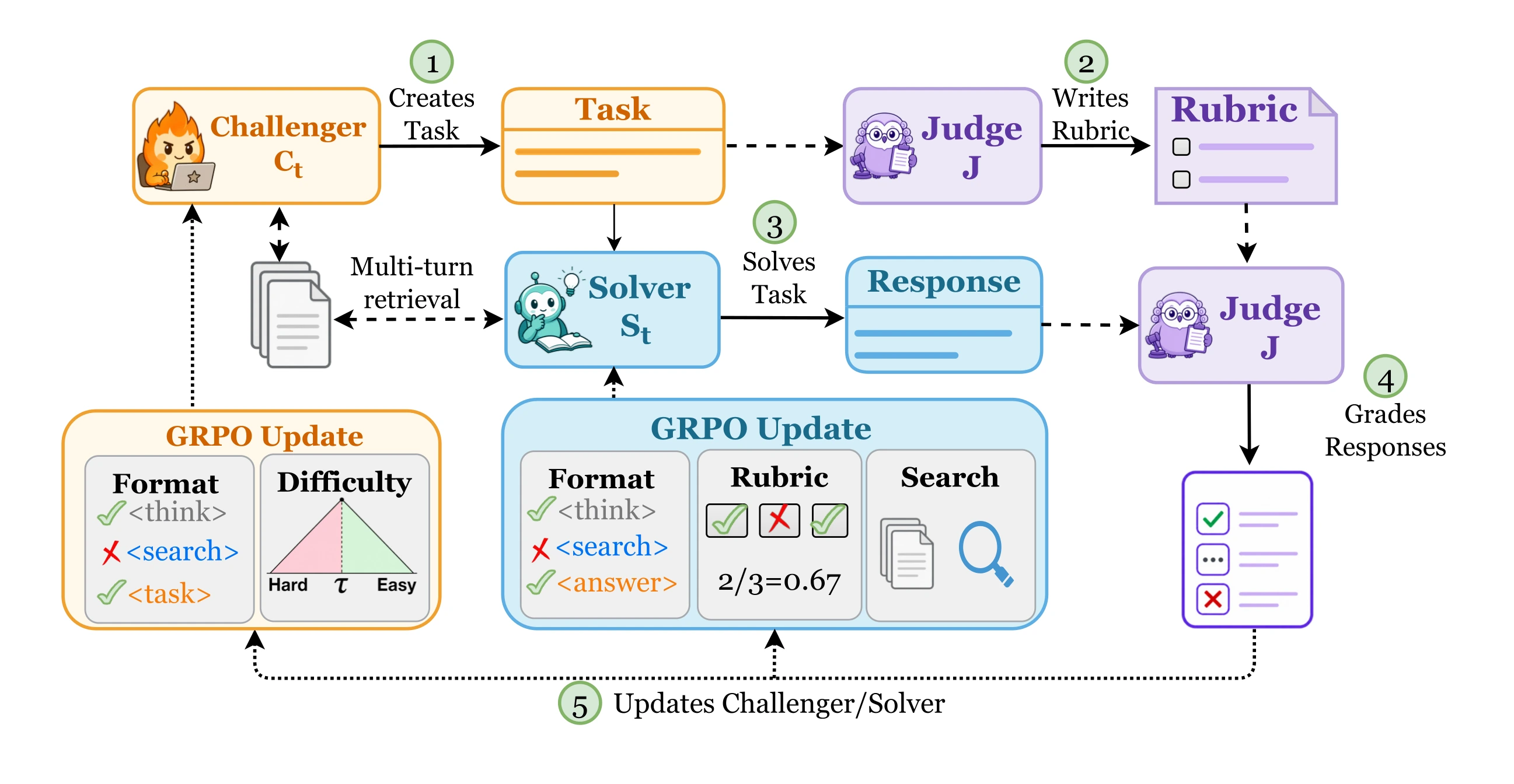
Challenger
Proposes tasks
Reads a corpus document via multi-turn retrieval and writes an open-ended task targeting the Solver's frontier. Rewarded when the Solver scores near 50%; tasks must pass the Judge's quality gates before entering training.